Настройка обработки событий
О настройке обработки событий
Для начала работы с R-Vision SIEM нужно создать коллектор и настроить в нём конвейер обработки событий. Все события, которые проходят через конвейер, сохраняются в связанном с ним хранилище. Хранилище находится в базе данных в виде таблицы, формат которой определяется моделью событий хранилища.
События из разнообразных источников проходят через конвейеры, настроенные на соответствующем коллекторе. Каждый конвейер может включать в себя различные этапы обработки, представленные соответствующими элементами, такими как коррелятор, нормализатор, агрегатор, VRL-трансформация и фильтр. Эти элементы конфигурируются на основе правил и условий, сформулированных на языке описания трансформаций и корреляций.
С помощью маршрутизатора и возможностей редактора конфигурации конвейера можно перенаправлять поток событий: сохранять их в хранилище и/или отправлять во внешние системы. Конвейер также может взаимодействовать с другими конвейерами посредством шины.
Таким образом полный цикл настройки системы для приёма и обработки событий включает в себя следующие этапы:
Шаг 1. Создание модели события
Модель события определяет формат хранилища событий: имена, типы полей и типы данных в полях. При создании хранилища событий обязательно указывается используемая в нем модель события.
Чтобы создать модель события:
-
Перейдите в раздел Ресурсы → Модели событий. Система отобразит сведения об имеющихся моделях событий, в том числе их статус (включена/выключена).
-
Нажмите на кнопку Создать (
 ). Отобразится окно создания модели события.
). Отобразится окно создания модели события. -
Введите название модели события.
-
Введите описание модели события.
-
В нижней части окна находится раздел Схема, содержащий список полей, которые будут использоваться в этой модели события.
По умолчанию система отображает набор служебных полей.
Список можно расширить, добавив вручную регулярные поля. Для этого:
-
Нажмите на кнопку Добавить строку. Система отобразит окно добавления поля.
-
Введите уникальный ключ идентификации нового поля.
-
При необходимости установите флажок Поле с изменяемой семантикой, чтобы использовать значения из другого поля при построении семантики названия нового поля. Выберите поле из выпадающего списка Поле, хранящее название, чтобы определить, какое поле будет использовать система для формирования его названия. Можно использовать только следующие типы полей: String, LCString, Enum.
-
Введите описание нового поля.
-
Выберите тип данных нового поля. В зависимости от выбранного типа данных необходимо указать его параметры:
-
Array — выберите тип элемента Array из списка.
-
Enum — укажите значения Enum, разделяя их запятой без пробелов.
-
KeyValue — выберите тип элемента KeyValue из списка.
-
UInt — выберите разрядность из списка.
-
-
При необходимости включите переключатель Может быть null, чтобы поле могло хранить значение типа
null. Если переключатель выключен, а поле не заполнено, событие в хранилище не будет создано.В полях типов Array, KeyValue, LCString этот переключатель не используется. -
При необходимости включите переключатель Отображать поле, чтобы поле отображалось в списке результатов поиска в разделе Поиск.
Эту настройку можно изменить при просмотре модели события или при настройке внешнего вида списка событий. -
Нажмите на кнопку Добавить.
Повторите действия, чтобы добавить несколько регулярных полей.
По умолчанию, универсальная модель содержит 150 служебных полей. Пользователь может добавить до 20 регулярных полей. При необходимости вы можете изменить или удалить добавленные регулярные поля:
-
Чтобы изменить поле, нажмите на кнопку
 в строке поля.
Отобразится окно изменения поля, в котором внесите требуемые изменения и нажмите на кнопку Сохранить. Измененные данные поля будут сохранены.
в строке поля.
Отобразится окно изменения поля, в котором внесите требуемые изменения и нажмите на кнопку Сохранить. Измененные данные поля будут сохранены. -
Чтобы удалить поле, нажмите на кнопку
 в строке поля. Поле будет удалено из списка полей модели события.
в строке поля. Поле будет удалено из списка полей модели события.
Служебные поля в модели данных создаются и заполняются автоматически и недоступны для изменения или удаления. -
-
-
Нажмите на кнопку Создать. Система создаст новую модель события и отобразит уведомление о ее добавлении. Модель отобразится в списке раздела Ресурсы → Модели событий.
Шаг 2. Регистрация базы данных событий
Базы данных (БД) событий используются для хранения событий в системе. Единицей хранения событий в БД является хранилище событий: на уровне БД хранилище представляет собой таблицу. Столбцы и типы данных хранилища задаются моделью события.
Чтобы зарегистрировать БД событий:
-
Перейдите в раздел Ресурсы → Базы данных событий. Система отобразит сведения об имеющихся БД событий.
-
Нажмите на кнопку Зарегистрировать (
). Отобразится окно регистрации БД событий. -
Введите название БД событий.
-
Введите уникальный идентификатор БД в системе обнаружения сервисов Consul.
-
При необходимости введите описание БД событий.
-
Нажмите на кнопку Зарегистрировать. Система создаст новую БД событий и отобразит уведомление о ее добавлении. БД отобразится в списке раздела Ресурсы → Базы данных событий.
Шаг 3. Создание хранилища событий
Хранилище событий используется для хранения событий, поступивших в систему и обработанных коллектором. Оно представляет собой таблицу в БД событий. Формат хранилища определяется его моделью событий.
Чтобы создать хранилище событий:
-
Перейдите в раздел Ресурсы → Хранилища событий. Система отобразит сведения об имеющихся хранилищах событий.
-
Нажмите на кнопку Создать (
). Отобразится окно создания хранилища событий. -
Выберите из выпадающего списка БД событий, в которую требуется поместить хранилище. Система отобразит в нижней части поля для настройки томов хранения этой БД.
-
Выберите из выпадающего списка модель события, которая будет использована для создаваемого хранилища.
-
Введите название хранилища событий.
-
При необходимости введите описание хранилища событий.
-
Задайте настройки хранения данных:
-
Выберите том хранения данных:
-
hot_volume — том для быстрого доступа к часто используемым данным (горячее хранение).
-
cold_volume — том для хранения редко используемых данных (холодное хранение).
-
-
Укажите срок хранения данных в днях.
Если поле для срока хранения данных оставить пустым, то срок хранения данных в этом хранилище будет неограниченным. -
Выберите из выпадающего списка действие над данными в томе по окончании срока хранения:
-
Переместить — данные будут перемещены в другой том. Система добавит дополнительную строку для настройки нового тома, в который требуется переместить данные.
-
Удалить — данные в томе будут удалены.
-
При необходимости можно задать настройки хранения данных на основе настроек по умолчанию в выбранной БД. Для этого нажмите на кнопку Применить настройки хранения по умолчанию БД. Если настройки по умолчанию не заданы, система отобразит соответствующее сообщение.
-
-
Нажмите на кнопку Создать. Система создаст новое хранилище событий и отобразит уведомление о его добавлении. Хранилище отобразится в списке раздела Ресурсы → Хранилища событий.
Шаг 4. Создание коллектора
Перед тем как система начнёт принимать события от источника данных, необходимо создать соответствующий коллектор.
Коллектор — это компонент системы, который обеспечивает сбор событий из источников, их обработку и дальнейшую отправку на хранение и/или во внешние системы. События поступают на коллектор через установленные на нем конвейеры, посредством которых они могут быть обработаны.
Чтобы создать коллектор:
-
Перейдите в раздел Ресурсы → Коллекторы. Система отобразит сведения об имеющихся коллекторах, в том числе их текущий статус (включен/выключен).
-
Нажмите на кнопку Создать (
). Отобразится окно создания коллектора. -
Введите название коллектора.
-
Укажите количество ядер процессора (CPU) и объем оперативной памяти (RAM), выделяемый для работы коллектора. Это можно сделать непосредственно в поле или с помощью кнопок
и  .
.-
Ресурсы, выделенные на работу коллектора, не используются в распределенной корреляции.
-
Каждая точка входа типа Database, размещенная на конвейере коллектора, использует 256 МБ оперативной памяти (RAM) из ресурсов коллектора. Если планируется размещение точек входа типа Database, необходимо учитывать их суммарное потребление памяти при распределении ресурсов коллектора.
-
-
При необходимости введите описание коллектора.
-
Для работы в режиме распределенной корреляции переведите переключатель Распределенный коррелятор в активное положение.
Изменение этой настройки потребует перезапуска коллектора. Если система работает на базе кластера Kubernetes с одним узлом, включение режима распределенной корреляции недоступно. -
Укажите количество ядер процессора (CPU) и объем оперативной памяти (RAM), выделяемый для работы распределенного коррелятора. Это можно сделать непосредственно в поле или с помощью кнопок
и .Операции полей joinиgroupдекларативного правила вычисляются на корреляторе. Остальные поля, в том числеaliasиfilter, вычисляются на предпроцессорах. В составе распределенного коррелятора может быть только один коррелятор, но несколько предпроцессоров.-
Укажите ресурсы для предпроцессора:
-
Выберите узел для размещения предпроцессора.
-
Укажите количество ядер процессора и объем оперативной памяти, выделяемые для работы предпроцессора.
-
-
Укажите ресурсы для коррелятора:
-
Выберите узел для размещения коррелятора.
-
Укажите количество ядер процессора и объем оперативной памяти, выделяемые для работы коррелятора.
-
-
-
Нажмите на кнопку Добавить предпроцессор, если необходимо добавить дополнительный предпроцессор.
-
При необходимости выберите уровень логирования из выпадающего списка Уровень логирования. Доступны следующие значения:
-
Error — записываются критические ошибки, которые могут влиять на работоспособность коллектора или препятствовать работе коллектора.
-
Warn — записываются предупреждения о потенциальных проблемах, которые могут требовать внимания, но не являются критическими.
-
Info — записывается общая информация о работе и состоянии коллектора.
-
Debug — записываются подробные отладочные сообщения, которые могут использоваться для диагностики и устранения проблем с коллектором.
-
Trace — самый подробный уровень логирования, предоставляющий внутреннюю информацию о каждом шаге работы коллектора.
-
-
Нажмите на кнопку Создать. Система создаст новый коллектор и отобразит уведомление о его добавлении. Коллектор отобразится в списке раздела Ресурсы → Коллекторы.
Шаг 5. Создание конвейера
Конвейер — это упорядоченная последовательность взаимосвязанных элементов, выполняющих различные этапы обработки событий. В процессе работы конвейера происходит прием событий, их нормализация, перенаправление, обогащение данными, фильтрация, агрегация, нормализация, корреляционный анализ и отправка как отдельных, так и сгруппированных или коррелированных событий для хранения и/или передачи во внешние системы.
Чтобы добавить конвейер:
-
Находясь в разделе Ресурсы → Коллекторы, нажмите на строку коллектора, созданного на шаге 4. Система отобразит в правой части экрана карточку этого коллектора с подробной информацией о нем.
-
Перейдите на вкладку Конвейеры в карточке коллектора. Система отобразит список конвейеров коллектора.
-
В нижней части окна нажмите на кнопку Добавить. На экране отобразится окно добавления конвейера.
-
Введите название конвейера.
-
При необходимости введите описание конвейера.
Установите флажок Открыть конфигурацию конвейера, чтобы сразу перейти в окно настроек конфигурации конвейера после его создания. -
Нажмите на кнопку Добавить. Система отобразит уведомление о добавлении конвейера. Новый конвейер появится в списке конвейеров на вкладке Конвейеры в карточке коллектора.
Шаг 6. Конфигурация конвейера
При настройке конвейера необходимо создать его компоненты, сконфигурировать их, упорядочить и объединить в последовательность, соответствующую логике обработки данных.
Чтобы настроить конвейер, требуется открыть его конфигурацию в режиме черновика. Если на шаге 5 флажок Открыть конфигурацию конвейера не был установлен, то выполните одно из действий:
-
Откройте карточку конвейера по стрелке (
 ) в его строке и нажмите на кнопку Конфигурация конвейера в нижней части карточки.
) в его строке и нажмите на кнопку Конфигурация конвейера в нижней части карточки. -
Нажмите на кнопку Действия (
 ) в строке конвейера и выберите опцию Конфигурация конвейера.
) в строке конвейера и выберите опцию Конфигурация конвейера.
В открытом окне конфигурации конвейера убедитесь, что в выпадающем списке Версия в правом верхнем углу окна выбран пункт Черновик.
Далее, рассмотрим сценарий настройки конфигурации конвейера для обработки исходных событий в формате JSON.
Пример исходного события, JSON
{
"event": "{\"host\":\"170.174.42.191\",\"user-identifier\":\"JohnDoe\",\"datetime\":\"31/Jul/2023:06:55:49\",\"method\":\"GET\",\"request\":\"/observability/metrics/production\",\"protocol\":\"HTTP/2.0\",\"status\":\"404\",\"bytes\":22427,\"referer\":\"https://example.url.com\"}
}
Добавление точки входа
Точка входа поставляет в систему поток сырых событий. Выбор формата точки входа зависит от формата данных, получаемых из источника события. Точка входа имеет один выход и не имеет входов.
Чтобы добавить точку входа на конвейер:
-
Нажмите на кнопку Добавить элемент и выберите из выпадающего списка пункт Точка входа. Отобразится окно добавления точки входа.
-
При необходимости выберите шаблон для автоматического заполнения полей точки входа. По умолчанию выбран вариант Без шаблона.
-
Заполните поля (набор и содержание полей могут отличаться в зависимости от типа точки):
-
Название точки входа.
-
Тип точки входа.
Каждая точка входа типа Database, размещенная на конвейере коллектора, использует 256 МБ оперативной памяти (RAM) из ресурсов коллектора. Если планируется размещение точек входа типа Database, необходимо учитывать их суммарное потребление памяти при распределении ресурсов коллектора.
-
Политика аудита источников.
Точка входа может быть привязана только к одной политике аудита источников, но к одной политике может быть привязано несколько точек входа. -
Формат точки входа.
-
Данные для подключения.
-
Настройки шифрования соединения (опционально).
-
Количество событий (опционально).
-
Интервал в секундах (опционально).
-
-
Установите флажок Сохранить как шаблон, если настройку точки входа необходимо сохранить в качестве шаблона для дальнейшего использования.
-
Нажмите Добавить. Новая точка входа отобразится на схеме.
Создадим точку входа с названием "JSON".
Добавление VRL-трансформации
VRL-трансформация служит для обработки и модификации событий с применением языка VRL. Этот элемент конвейера принимает на вход события, проводит их преобразование и на выходе предоставляет уже модифицированные события.
Чтобы добавить VRL-трансформацию на конвейер:
-
Нажмите на кнопку Добавить элемент и выберите из выпадающего списка пункт VRL-трансформация. Отобразится окно добавления VRL-трансформации.
-
При необходимости выберите шаблон для автоматического заполнения полей VRL-трансформации. По умолчанию выбран вариант Без шаблона.
-
Введите название VRL-трансформации.
-
Введите правило, по которому будет преобразовываться событие, на языке VRL.
В редакторе кода доступны горячие клавиши. -
При необходимости из выпадающего списка Обработка ошибок выберите шину коллектора, в которую будет отправлено событие в случае возникновения ошибок обработки. По умолчанию выбран вариант События с ошибкой.
-
Установите флажок Сохранить как шаблон, если настройку VRL-трансформации необходимо сохранить в качестве шаблона для дальнейшего использования.
-
Нажмите на кнопку Добавить. Новая VRL-трансформация отобразится на схеме.
Пример:
Добавим условие на языке VRL, согласно которому исходное событие будет обогащаться дополнительным полем responseStatus. В нем будет устанавливаться значение "Bad request", если в поле status приходящего на VRL-трансформация события установлено значение 401 или 404.
Для этого в свойствах VRL-трансформации пропишем следующее условие:
Пример условия обогащения событий, язык VRL
if .status == "404" || .status == "401" {
.responseStatus = "Bad request"
}
Интерпретация
if .status == "404" || .status == "401":
-
Условное выражение проверяет, равно ли значение поля
statusсобытия строке "404" или "401".
.responseStatus = "Bad request":
-
Если условие выше выполняется, то поле
responseStatusтекущего события устанавливается в значение "Bad request".
Создадим VRL-трансформацию с названием "Assign responseStatus", используя код выше.
Добавление маршрутизатора
Маршрутизатор направляет события на разные этапы обработки в зависимости от их содержимого или других условий. Маршрутизатор имеет один вход и несколько выходов. На входе каждое событие проверяется по условиям и появляется на тех выходах, где условие выполняется.
Чтобы добавить маршрутизатор на конвейер:
-
Нажмите на кнопку Добавить элемент и выберите из выпадающего списка пункт Маршрутизатор. Отобразится окно добавления маршрутизатора.
-
Введите название маршрутизатора.
Для маршрутизатора недопустимо использование названий "_unmatched" и "_default". -
Настройте список маршрутов маршрутизатора.
-
Нажмите кнопку Добавить маршрут.
-
Введите название маршрута.
-
Задайте правило обработки событий на языке VRL.
-
Нажмите на кнопку Добавить. Маршрут будет добавлен в маршрутизатор.
-
-
При необходимости установите флажок Добавить маршрут по умолчанию. В этом случае к маршрутизатору будет добавлен маршрут По умолчанию, на выход которого будут попадать те события, которые не удовлетворяют условиям остальных маршрутов.
При неустановленном флажке события, не удовлетворяющие условиям ни одного из маршрутов, будут удаляться.
-
Нажмите на кнопку Добавить. Новый маршрутизатор отобразится на схеме.
Пример:
Добавим маршрутизатор, который проверяет статус события, после чего:
-
Отправляет события со статусом 400, 401, 403 и 404 на дальнейшую обработку.
-
Отправляет события со статусом 500, 502 и 504 на хранение.
Добавим два маршрута со следующими условиями:
.event.status == "400" || .event.status == "401" || .event.status == "403" || .event.status == "404"
.event.status == "500" || .event.status == "502" || .event.status == "504"
Создадим маршрутизатор с названием "StatusCheckRouter" и двумя маршрутами, используя условия выше, а также маршрутом по умолчанию. Первому маршруту дадим название "ClientErrorRoute", второму — "ServerErrorRoute".
Добавление фильтра
Фильтр предназначен для сокращения объема обрабатываемых событий путём их отсеивания на основе заданных условий. Условия обычно формулируются через имена полей и их значения, и для их определения используются математические и логические операторы. Например, условие externalId == "4648" && categoryOutcome == "Success" позволяет пропустить через фильтр только те события, которые удовлетворяют этим критериям.
У фильтра есть один вход и один выход. На вход фильтра подается событие, и если оно соответствует заданным условиям, то проходит на выход. В противном случае событие отсеивается и не участвует в дальнейшей обработке.
Чтобы добавить фильтр на конвейер:
-
Нажмите на кнопку Добавить элемент и выберите из выпадающего списка пункт Фильтр. Отобразится окно добавления фильтра.
-
При необходимости выберите шаблон для автоматического заполнения полей фильтра. По умолчанию выбран вариант Без шаблона.
-
Введите название фильтра.
-
Задайте условие фильтрации входящих событий на языке VRL.
Условия обычно формулируются через имена полей и их значения, и для их определения используются математические и логические операторы.
В редакторе кода доступны горячие клавиши. -
Установите флажок Сохранить как шаблон, если настройку фильтра необходимо сохранить в качестве шаблона для дальнейшего использования.
-
Нажмите на кнопку Добавить. Новый фильтр отобразится на схеме.
Пример:
Добавим фильтр, который пропускает только события с хоста 170.174.42.191.
В поле Условие фильтра пропишем следующее условие:
.event.host == "170.174.42.191"
Создадим фильтр с названием "FilterByHost" используя условие выше.
Настройка агрегации событий
Чтобы события, проходящие через конвейер обработки событий, агрегировались, необходимо добавить на конвейер агрегатор.
Чтобы добавить агрегатор, необходимо создать и установить на нем правило агрегации, согласно которому агрегатор будет объединять поступающие на него события.
Создание правила агрегации
Правило агрегации в системе R-Vision SIEM является структурированным объектом данных в формате RObject (.ro), описывающим процесс объединения и анализа групп событий безопасности. Основная функция правила агрегации — сбор и объединение данных из различных событий в рамках заданной логики агрегации. Каждое правило агрегации включает в себя критерии для группировки событий, условия начала и завершения агрегации, а также стратегии агрегации для каждого поля. Агрегация инициируется в соответствии с условиями, определенными в правилах, и преобразует входящий поток событий в агрегированные данные.
Чтобы добавить правило агрегации:
-
Перейдите в раздел Экспертиза. Система отобразит сведения об имеющихся элементах экспертизы, в том числе их текущий статус (включен/выключен).
-
Нажмите на кнопку Создать и выберите из выпадающего списка пункт Правило агрегации. Система отобразит окно создания правила агрегации.
Пример правила агрегации, схема RObject
# Уникальный идентификатор правила. id: example/network_activity_rule # Название правила. name: NetworkActivityAggregationRule # Тип элемента экспертизы. type: aggregation_rule # Версия правила. version: 1.0.0 # Описание назначения правила. description: Агрегация событий сетевой активности для анализа трафика # Имя и контактные данные автора правила. author: John Doe <johndoe@example.com> # Список совместимых с правилом источников данных. data_source: - platform: Windows - source: Sysmon - events: - EventID_1 - EventID_2 # Теги, связанные с правилом. tags: - network - traffic_analysis # Отбрасывает события, которые не соответствуют критериям. filter: !vrl | # Фильтрует события, не относящиеся к категории "Network" или имеющие низкий уровень серьезности. .category == "Network" && .severity > 3 # Группировка событий по источнику и назначению. group_by: - src_ip - dest_ip # Условие открытия агрегационного окна. start_when: !vrl | # Начинаем агрегацию при обнаружении события начала соединения. .event_type == "connection_start" # Максимальное количество событий. max_events: 5 # Время ожидания последнего события (миллисекунды). expire_after_ms: 60000 # Интервал проверки окон агрегации (миллисекунды). flush_period_ms: 2000 # Стратегии агрегации значений для каждого указанного поля. merge_strategies: bytes_sent: sum bytes_received: sum # Тесты для проверки работы правила. tests: - name: Network Activity Test events: - {"category":"Network", "severity":5, "event_type":"connection_start", "src_ip":"192.0.2.10", "dest_ip":"192.0.2.20", "bytes_sent":1500, "bytes_received":2000} - {"category":"Network", "severity":4, "event_type":"data_transfer", "src_ip":"192.0.2.10", "dest_ip":192.0.2.20", "bytes_sent":3000, "bytes_received":4000} - {"category":"Network", "severity":5, "event_type":"connection_end", "src_ip":"192.0.2.10", "dest_ip":"192.0.2.20", "bytes_sent":500, "bytes_received":600} assertion: !vrl | # Проверяем, что агрегированные значения соответствуют ожиданиям. assert_eq!(.[0], { "category": "Network", "event_type": "connection_start", "src_ip": "192.0.2.10", "dest_ip": "192.0.2.20", "bytes_sent": 5000, "bytes_received": 6600 })Интерпретация
Метаданные правила:
-
id: уникальный идентификатор правила в системе. -
name: название правила. -
type: типaggregation_ruleуказывает на то, что это правило агрегации. -
version: версия правила. -
description: описывает цель правила — "Агрегация событий сетевой активности для анализа трафика". -
author: создатель правила. -
tags: тегиnetworkиtraffic_analysisклассифицируют правило по его функциональности и области применения.
Фильтрация событий (filter):
-
filter: фильтрует события по категории "Network" и уровню серьезности более 3. Это сужает область применения правила только к событиям, которые удовлеворяют условиям фильтрации.
Группировка событий (group_by):
-
group_by: группирует события по полямsrc_ipиdest_ip. Это позволяет анализировать взаимодействия между конкретными источниками и назначениями в сети.
Условие начала агрегации (starts_when):
-
starts_when: определяет начало агрегации при появлении событий типа "connection_start", что является признаком начала нового сетевого соединения.
Параметры агрегационного окна (max_events, expire_after_ms, flush_period_ms):
-
max_events: ограничивает количество событий в агрегации до 5. После достижения этого количества, агрегационное окно закрывается и генерируется агрегированное событие. -
expire_after_ms: устанавливает максимальный период ожидания последнего события в агрегационном окне в 60000 миллисекунд (1 минута). -
flush_period_ms: задает частоту проверки и закрытия агрегационных окон в 2000 миллисекунд (2 секунды).
Стратегии агрегации (merge_strategies):
-
merge_strategies: определяет, как будут объединяться поля событий. Для "bytes_sent" и "bytes_received" применяется стратегия суммирования (sum).
Тестирование правила (tests):
-
name: "Network Activity Test" — название теста. -
events: описывает ряд тестовых событий, имитирующих реальный сетевой трафик, для проверки эффективности правила. -
assertion: проверяет, что правило корректно агрегирует события и вычисляет суммы переданных и полученных байтов. Это подтверждает, что правило работает как предполагалось и агрегирует данные согласно заданным критериям.
Обработка событий правилом агрегации
Проанализируем работу правила агрегации "NetworkActivityAggregationRule", фокусируясь на процессе обработки событий.
Представим, что на агрегатор поступает поток сетевых событий, которые соответствуют критериям, заданным в фильтре
filterправила. Эти события содержат данные о типе сетевого соединения, IP-адресах источника и назначения, а также объёме переданных и полученных данных.{ "category": "Network", "severity": 5, "event_type": "connection_start", "src_ip": "192.168.1.10", "dest_ip": "192.168.1.20", "bytes_sent": 1500, "bytes_received": 2000 }По мере поступления этих событий, они фильтруются правилом "NetworkActivityAggregationRule". Правило агрегирует события, группируя их по IP-адресам источника и назначения (
group_by). Таким образом, события, исходящие от одной пары IP-адресов, объединяются в одно агрегированное событие.Агрегация инициируется, когда обнаруживается событие типа
connection_start(starts_when). Правило продолжает агрегировать события до тех пор, пока не будет достигнуто максимальное количество событий (max_events) или не истечёт время ожидания (expire_after_ms).Агрегированное событие включает в себя сумму значений
bytes_sentиbytes_receivedдля всех событий в группе (merge_strategies).{ "event_type": "aggregated_network_activity", "src_ip": "192.168.1.10", "dest_ip": "192.168.1.20", "total_bytes_sent": 5000, "total_bytes_received": 6600 }Данное агрегированное событие отражает общую активность между двумя конкретными IP-адресами, позволяя идентифицировать аномалии или необычную активность в сети.
-
-
Заполните поля правила агрегации, чтобы определить логику его работы, и нажмите на кнопку Опубликовать версию. Система отобразит уведомление об успешном создании правила. Новое правило агрегации отобразится в таблице раздела Экспертиза.
-
Чтобы созданное правило стало доступным в конвейерах событий, включите его:
-
Нажмите на строку с созданным правилом агрегации. Система отобразит в правой части экрана карточку этого правила с подробной информацией о нем.
-
Убедитесь, что в карточке открыта вкладка Информация.
-
Переведите переключатель состояния правила в верхней части карточки в активное положение и подтвердите включение правила. Система обновит информацию о статусе правила агрегации.
-
Добавление агрегатора
Агрегатор представляет собой компонент конвейера, который использует правила агрегации для объединения и анализа групп событий безопасности.
Порядок применения правил агрегации определяется последовательностью их добавления в агрегатор. Это позволяет управлять процессом агрегации и определять, какие события будут объединены вместе.
Агрегатор на входе принимает поток событий, производит их агрегацию и выдает агрегированные события на выходе.
Чтобы добавить агрегатор на конвейер:
-
Откройте окно конфигурации конвейера, созданного на шаге 5. Убедитесь, что в выпадающем списке в правом верхнем углу окна выбран пункт Черновик.
-
Нажмите на кнопку Добавить элемент и выберите из выпадающего списка пункт Агрегатор. Отобразится окно добавления агрегатора.
-
Введите название агрегатора.
-
Добавьте в агрегатор правила агрегации.
Чтобы добавить правило агрегации:
-
Раскройте дерево каталогов в левой части окна и выберите каталог, который содержит нужное правило агрегации.
-
Установите флажок слева от правила агрегации, которое необходимо добавить в агрегатор.
-
-
Нажмите на кнопку Добавить. Новый агрегатор отобразится на схеме.
Добавим агрегатор с правилом NetworkActivityAggregationRule на конвейер. В названии агрегатора укажем "AggregateEvents".
Настройка нормализации событий
Чтобы события, проходящие через конвейер обработки событий, нормализовывались, необходимо добавить на конвейер нормализатор.
Чтобы добавить нормализатор, необходимо создать и установить на нем правило нормализации, согласно которому нормализатор будет обрабатывать поступающие на него данные и нормализовывать их.
Создание правила нормализации
Правила нормализации в системе R-Vision SIEM обрабатывают и преобразовывают поступающие события согласно условиям и коду нормализации, составленным на языке VRL и условию, заданному в поле filter.
Чтобы добавить правило нормализации:
-
Перейдите в раздел Экспертиза. Система отобразит сведения об имеющихся элементах экспертизы, в том числе их текущий статус (включен/выключен).
-
Нажмите на кнопку Создать и выберите из выпадающего списка пункт Правило нормализации. Система отобразит окно создания правила нормализации.
Пример правила нормализации, схема RObject.
# Уникальный идентификатор правила. id: example/basic_normalization_rule # Название правила. name: BasicNormalizationRule # Имя автора правила. author: John Doe <johndoe@example.com> # Версия правила. version: 1.0.0 # Описание назначения правила. description: Базовое правило нормализации # Список совместимых с правилом источников данных. data_source: - platform: Windows - source: Sysmon - events: - logs/default.log - logs/somelog.log # Теги, связанные с правилом. tags: - normalization - security # Тип элемента экспертизы. type: normalization_rule # Блок правил на языке VRL c условиями фильтрации событий. filter: !vrl | .event.host == "198.51.100.191" # Блок с правилами на языке VRL для нормализации полей события. normalizer: !vrl | e = parse_json(.event) ?? {} . |= { "timestamp": parse_timestamp(e.datetime, "%d/%b/%Y:%H:%M:%S") ?? now(), "source": "normalized", "status": .event.status } if e.status == "404" || e.status == "401" { .responseStatus = "Bad request" }Интерпретация
Поле
filter:.event.host == "170.174.42.191":Сравнения поля
hostсо значением "170.174.42.191" в сыром событии. Если значение поляhostв сыром событии совпадает с "170.174.42.191", то событие будет нормализовано согласно правилам в полеnormalizer. Если значение поляhostне совпадает с указанным IP-адресом, правила нормализации к событию применены не будут.Поле
normalizer:e = parse_json(.event) ?? {}:-
Попытка преобразовать содержимое поля
.eventиз формата JSON в структуру данных VRL. -
Если преобразование не удалось или результатом является
null, переменнойeбудет присвоен пустой объект{}, что достигается с помощью оператора??.
. |= { … }:-
Оператор обновления/добавления новых полей к текущему объекту на основе значений из объекта
e.
Структура, которая присваивается текущему объекту:
-
userId: Присваивает значение поляuser-identifierиз объектаeк полюuserIdтекущего объекта. -
timestamp: Преобразует строковое значение поляdatetimeиз объектаeв метку времени с использованием указанного формата. Если преобразование не удастся или значение поляdatetimeравноnull, будет использовано текущее время, возвращаемое функциейnow(). -
host: Присваивает значение поляhostиз объектаeк полюhostтекущего объекта. -
method: Присваивает значение поляmethodиз объектаeк полюmethodтекущего объекта. -
path: Присваивает значение поляrequestиз объектаeк полюpathтекущего объекта. -
protocol: Присваивает значение поляprotocolиз объектаeк полюprotocolтекущего объекта.
if e.status == "404" || e.status == "401":-
Условное выражение проверяет, равно ли значение поля
statusиз объектаeстроке "404" или "401".
.responseStatus = "Bad request":-
Если условие выше выполняется, то поле
responseStatusтекущего объекта устанавливается в значение "Bad request".
if e.protocol == "HTTP/2.0":-
Условное выражение проверяет, равно ли значение поля
protocolиз объектаeстроке "HTTP/2.0".
.protocol = "HTTP/2":-
Если условие выше выполняется, то поле
protocolтекущего объекта заменяется на значение "HTTP/2".
Обработка событий правилом нормализации
Рассмотрим работу правила на примере разбора базового (сырого) события.
Допустим, на нормализатор поступают события следующего вида:
Example 4. Исходное событие, JSON{ "event": "{\"host\":\"170.174.42.191\",\"user-identifier\":\"JohnDoe\",\"datetime\":\"31/Jul/2023:06:55:49\",\"method\":\"GET\",\"request\":\"/observability/metrics/production\",\"protocol\":\"HTTP/2.0\",\"status\":\"404\",\"bytes\":22427,\"referer\":\"https://example.url.com\"}" }После применения к событию правила "BasicNormalizationRule", оно принимает следующий вид:
Example 5. Нормализованное событие, JSON{ "event": "{\"host\":\"170.174.42.191\",\"user-identifier\":\"JohnDoe\",\"datetime\":\"31/Jul/2023:06:55:49\",\"method\":\"GET\",\"request\":\"/observability/metrics/production\",\"protocol\":\"HTTP/2.0\",\"status\":\"404\",\"bytes\":22427,\"referer\":\"https://example.url.com\"}", "host": "170.174.42.191", "method": "GET", "path": "/observability/metrics/production", "protocol": "HTTP/2", "referer": "https://example.url.com", "responseBytes": 22427, "responseStatus": "Bad request", "serverIP": "170.174.42.191", "timestamp": "2023-07-30T23:55:49Z", "userAgent": null, "userId": "JohnDoe" }Событие удовлетворяет условию из поля
filter, следовательно, оно подлежит нормализации и обрабатывается согласно правилам из поляnormalizer. В структуре нормализованного события в полеeventзаписывается исходное событие. Прочие поля добавляются к объекту и определяются в соответствии с правилами нормализации, хранящимся в полеnormalizer. -
-
Заполните поля правила нормализации, чтобы определить логику его работы, и нажмите на кнопку Опубликовать версию. Система отобразит уведомление об успешном создании правила. Новое правило нормализации отобразится в таблице раздела Экспертиза.
-
Чтобы созданное правило стало доступным в конвейерах событий, включите его:
-
Нажмите на строку с созданным правилом нормализации. Система отобразит в правой части экрана карточку этого правила с подробной информацией о нем.
-
Убедитесь, что в карточке открыта вкладка Информация.
-
Переведите переключатель состояния правила в верхней части карточки в активное положение и подтвердите включение правила. Система обновит информацию о статусе правила нормализации.
-
Добавление нормализатора
Нормализатор представляет собой комплекс правил нормализации. Каждое такое правило состоит из двух основных компонентов: кода нормализации, выполненного на языке VRL, и фильтра. В случае наличия фильтра, выполнение соответствующего правила нормализации инициируется только при соблюдении условий этого фильтра для входящего события.
Порядок применения правил нормализации определяется последовательностью их добавления в нормализатор. Таким образом, события проходят через набор правил в установленном порядке, что позволяет осуществлять сложные сценарии нормализации данных.
Нормализатор на входе принимает события, преобразует/обогащает их и выдает преобразованные события на выходе.
Чтобы добавить нормализатор на конвейер:
-
Откройте окно конфигурации конвейера, созданного на шаге 5. Убедитесь, что в выпадающем списке в правом верхнем углу окна выбран пункт Черновик.
-
Нажмите на кнопку Добавить элемент и выберите из выпадающего списка пункт Нормализатор. Отобразится окно добавления нормализатора.
-
Введите название нормализатора.
-
При необходимости из выпадающего списка Обработка ошибок выберите шину коллектора, в которую будет отправлено событие в случае возникновения ошибок обработки. По умолчанию выбран вариант События с ошибкой.
-
Добавьте в нормализатор правила нормализации.
Чтобы добавить правило нормализации:
-
Раскройте дерево каталогов в левой части окна и выберите каталог, который содержит нужное правило нормализации.
-
Установите флажок слева от правила нормализации, которое необходимо добавить в нормализатор.
-
-
Нажмите на кнопку Добавить. Новый нормализатор отобразится на схеме.
Добавим нормализатор с правилом BasicNormalizationRule на конвейер. В названии нормализатора укажем "Normalization".
Настройка корреляции событий
Чтобы события, поступающие на конвейер, коррелировались, необходимо добавить на конвейер коррелятор.
Чтобы добавить коррелятор, необходимо создать и установить в нём правило корреляции. Правила корреляции определяют, как коррелятор будет обрабатывать входящие данные и формировать на их основе корреляционные события.
Создание правила корреляции
Правила корреляции в системе R-Vision SIEM позволяют обнаруживать и анализировать взаимосвязанные события, соответствующие определенным правилам, написанным на языке описания преобразований и корреляций. Эти правила также могут инициировать действия после обнаружения, такие как создание корреляционных событий и оповещений.
Чтобы добавить правило корреляции:
-
Перейдите в раздел Экспертиза. Система отобразит сведения об имеющихся элементах экспертизы, в том числе их текущий статус (включен/выключен).
-
Нажмите на кнопку Создать и выберите из выпадающего списка пункт Правило корреляции. Система отобразит окно выбора способа создания правила.
-
Выберите способ создания правила через код и нажмите на кнопку Создать. Система отобразит окно задания RObject-конфигурации правила корреляции.
Пример правила корреляции, схема RObject
# Уникальный идентификатор правила. id: example/ddos_detection_rule # Название правила. name: DDoSDetectionRule # Тип элемента экспертизы. type: correlation_rule # Версия правила. version: 1.0.0 # Уровень угрозы, присваиваемый корреляционному правилу. severity: high # Описание назначения правила. description: Обнаружение атаки DDoS на основе трафика # Имя и контактные данные автора правила. author: John Doe <johndoe@example.com> # Список совместимых с правилом источников данных. data_source: - platform: Windows - source: Sysmon - events: - EventID_13 - EventID_1 # Теги, связанные с правилом. tags: - ddos - security # Фильтр применяется к событиям перед входом в правило. filter: !vrl | .source_ip != null && .request_path != null # Разделение потоков событий на псевдонимы. aliases: HighRateTraffic: filter: !vrl | .event_type == "HTTP_REQUEST" && parse_duration!(.window, "s") >= 100 SuspiciousPatterns: filter: !vrl | .event_type == "HTTP_REQUEST" && ends_with(to_string!(.request_path), "/api/highload") NormalTraffic: filter: !vrl | .event_type == "HTTP_REQUEST" && ends_with(to_string!(.request_path), "/home") # Соединение потоков событий. select: alias: HighRateTraffic join: alias: SuspiciousPatterns absent: true on: - eq: { HighRateTraffic: .source_ip, SuspiciousPatterns: .source_ip } wait_for: 30 # Группировка событий. group: - alias: HighRateTraffic by: - source_ip count: 3 # Частота генерации корреляционных событий в рамках каждой группы (событий в секунду). throttle_time_sec: 60 # Время хранения промежуточных корреляционных данных (секунды). ttl: 60 # Логика обогащения корреляционного события на языке VRL. on_correlate: !vrl | .message = "Обнаружена потенциальная DDoS атака с источника: " + to_string!(.source_ip) .additional_info = "Высокая частота запросов и подозрительные паттерны в пути запроса /api/highload" # Управляет созданием оповещений по результатам корреляции. trigger_alert: true # Тесты для проверки работы правила. tests: - name: DDoS Attack Detected events: - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.1", "window": "100s", "request_path": "/api/highload" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.1", "window": "110s", "request_path": "/api/highload" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.2", "window": "120s", "request_path": "/api/highload" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.100", "window": "130s", "request_path": "/api/highload" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.132", "window": "140s", "request_path": "/api/highload" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.1", "window": "150s", "request_path": "/api/highload" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.1", "window": "160s", "request_path": "/api/highload" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.1", "window": "170s", "request_path": "/api/highload" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.132", "window": "180s", "request_path": "/api/highload" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.1", "window": "190s", "request_path": "/api/highload" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.132", "window": "50s", "request_path": "/home" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.1", "window": "160s", "request_path": "/api/highload" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.1", "window": "170s", "request_path": "/api/highload" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.1", "window": "180s", "request_path": "/api/highload" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.1", "window": "190s", "request_path": "/api/highload" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.1", "window": "50s", "request_path": "/home" } = - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.224", "window": "60s", "request_path": "/contact" } - { "event_type": "HTTP_REQUEST", "source_ip": "192.0.2.10", "window": "70s", "request_path": "/about" } assertion: !vrl | assert_eq!(.message, "Обнаружена потенциальная DDoS атака с источника: 192.0.2.1")Интерпретация
Правило корреляции "DDoSDetectionRule" предназначено для выявления DDoS-атак на основе анализа потока поступающих событий.
Метаданные правила:
-
id: уникальный идентификатор правила в системе. -
name: название правила. -
type: типcorrelation_ruleуказывает на то, что это правило корреляции. -
version: версия правила. -
description: описывает цель правила — "Обнаружение атаки DDoS на основе трафика". -
author: создатель правила. -
tags: тегиddosиsecurityклассифицируют правило по его функциональности и области применения.
Логика фильтрации (filter):
-
Условия фильтрации
.source_ip != nullи.request_path != nullвыбирают события, у которых есть IP-адрес источника и путь запроса.
Логика фильтрации (aliases):
-
Псевдоним
HighRateTraffic: фильтр для событий с высокой частотой запросов, идентифицируемых поevent_type == "HTTP_REQUEST"иparse_duration!(.window) >= 100. Отбирает события с частотой запросов, превышающей или равной 100 запросов в определенный временной интервал. -
Псевдоним
SuspiciousPatterns: фильтр для событий с подозрительными путями запроса, определяемый какevent_type == "HTTP_REQUEST"иends_with(to_string!(.request_path), "/api/highload"). Отбирает запросы, пути которых оканчиваются на "/api/highload".
Соединение потоков событий (select и join):
-
Выбор и соединение (
selectиjoin) потоков событийHighRateTrafficиSuspiciousPatternsосуществляется на основе совпаденияsource_ip. Это соединение позволяет коррелировать высокочастотные запросы с подозрительными паттернами, исходящими от одного источника. -
В поле
wait_forопределяется, что система должна ожидать в течение 30 секунд перед тем, как принять решение о соединении событий из различных псевдонимов. Это значит, что система будет накапливать события в течение указанного времени с момента получения первого события и затем анализировать их на предмет соответствия заданным критериям соединения. -
В операции соединения с
SuspiciousPatternsиспользуется полеabsent: true, что указывает на то, что отсутствие события изSuspiciousPatternsв течение 30 секунд будет добавлено в цепочку корреляционных событий.
Группировка событий (group):
-
group: группировка событий применяется к псевдонимуHighRateTrafficпо полюsource_ip, что позволяет агрегировать и анализировать события, исходящие от одного источника IP. Количество событий для формирования группы в полеcountустановлено в 10, что означает, что группа будет сформирована при накоплении 3 событий от одного источника IP. -
throttle_time_sec: задает интервал времени в секундах между генерацией корреляционных событий в рамках каждой группы событий. Например, 60 секунд.
Срок хранения промежуточных данных корреляции (ttl):
-
ttlна уровне правила задает общее максимальное время жизни промежуточных корреляционных данных. Например, 60 секунд. Это время определяет, как долго промежуточные результаты для всей цепочки событий будут храниться в памяти до их автоматического удаления, если корреляция не завершается.
Пост-корреляционная логика (on_correlate):
-
on_correlate: обогащает корреляционное событие полями.messageи.additional_info. -
trigger_alert: управляет созданием оповещений по результатам корреляции. В данном случае, сtrigger_alert: true, система будет генерировать оповещения при успешной корреляции событий.
По накоплении 3 событий правило генерирует корреляционное событие со следующими атрибутами:
-
type: "correlation_rule", -
event_type: "DDoS Detection", -
source_ip: "192.168.1.1", -
datetime: "2023-09-28T12:45:00Z", -
message: "Обнаружена потенциальная DDoS атака с источника: 192.168.1.1", -
additional_info: "Высокая частота запросов и подозрительные паттерны в пути запроса /api/highload"
Тестирование правила (tests):
-
Набор тестовых сценариев "DDoS Attack Detected" включает набор событий, часть из которых имитируют характеристики DDoS-атаки, а остальные являются контрольными примерами обычного трафика. Цель тестирования — подтвердить, что правило корректно идентифицирует только события, связанные с DDoS-атаками и игнорирует неподходящие события. Тесты включают события с HTTP-запросами, различающимися по
source_ipиrequest_path, что позволяет проверить способность правила различать атакующий трафик от легитимного. -
События, моделирующие DDoS-атаку, имеют одинаковый
source_ipи конечный путь запроса "/api/highload", что соответствует фильтрамHighRateTrafficиSuspiciousPatterns. Это сценарий, в котором ожидается активация правила и генерация корреляционного события. -
Контрольные события с разными
source_ipи неподозрительными путями запроса ("/home", "/contact", "/about") предназначены для подтверждения, что правило не реагирует на обычные запросы, не связанные с DDoS-активностью.
assertionв тестовом блоке предназначен для проверки того, что только события, соответствующие характеристикам DDoS-атаки, приводят к формированию корреляционного события с ожидаемым сообщением об обнаружении атаки.Обработка событий правилом корреляции
Проанализируем логику работы правила "DDoSDetectionRule", фокусируясь на процессе обработки событий.
Предположим, что за короткий промежуток времени на коррелятор, на котором установлено правило "DDoSDetectionRule", поступает поток JSON-событий от различных источников IP, включая множество запросов с IP-адреса "192.168.1.1". Эти события соответствуют критериям, заданным в фильтрах
HighRateTrafficиSuspiciousPatterns.Example 6. Исходное событие, JSON{ "event_type": "HTTP_REQUEST", "source_ip": "192.168.1.x", // где x - уникальный номер для каждого события "datetime": "2023-09-28T12:34:56Z", "request_path": "/api/highload", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (HTML, like Gecko) Chrome/93.0.4472.124 Safari/537.36" }По мере поступления этих событий, они фильтруются правилом "DDoSDetectionRule". Фильтр
HighRateTrafficотбирает события, соответствующие запросам с высокой частотой (более 100 запросов за заданный временной интервал), аSuspiciousPatternsфокусируется на запросах с определенным путем запроса/api/highload.Когда события от одного источника IP, например, "192.168.1.1", соответствуют обоим фильтрам и проходят через механизм соединения
join, правило "DDoSDetectionRule" приступает к группировке. Правило использует полеgroupдля агрегирования событий от одного источника IP. Если количество событий от одного источника соответствует заданному порогу в 3 события, правило генерирует корреляционное событие.Example 7. Корреляционное событие, генерируемое правилом "DDoSDetectionRule"{ "type": "correlation_rule", "severity": "high", "event_type": "DDoS Detection", "source_ip": "192.168.1.1", "datetime": "2023-09-28T12:45:00Z", "message": "Обнаружена потенциальная DDoS атака с источника: 192.168.1.1", "additional_info": "Высокая частота запросов и подозрительные паттерны в пути запроса /api/highload" }Данное корреляционное событие указывает на то, что система обнаружила аномальную активность, соответствующую критериям DDoS-атаки, исходящей с одного IP-адреса. Правило "DDoSDetectionRule" коррелирует события, основываясь на двух ключевых факторах: частоте запросов и специфических путях запросов, что является индикатором потенциальной атаки.
-
-
Заполните поля правила корреляции, чтобы определить логику его работы, и нажмите на кнопку Опубликовать версию. Система отобразит уведомление об успешном создании правила. Новое правило корреляции отобразится в таблице раздела Экспертиза.
-
Чтобы созданное правило стало доступным в конвейерах событий, включите его:
-
Нажмите на строку с созданным правилом корреляции. Система отобразит в правой части экрана карточку этого правила с подробной информацией о нем.
-
Убедитесь, что в карточке открыта вкладка Информация.
-
Переведите переключатель состояния правила в верхней части карточки в активное положение и подтвердите включение правила. Система обновит информацию о статусе правила корреляции.
-
| В примере рассматривается способ создания правила корреляции через код. Для правила корреляции доступен также способ построения через специальный конструктор. |
Добавление коррелятора
Коррелятор позволяет связывать различные события и создавать комплексные правила на их основе. На входе применяет правила корреляции к потоку событий. На выходе выдает корреляционные события.
Чтобы добавить коррелятор на конвейер:
-
Откройте окно конфигурации конвейера, созданного на шаге 5. Убедитесь, что в выпадающем списке в правом верхнем углу окна выбран пункт Черновик.
-
Нажмите на кнопку Добавить элемент и выберите из выпадающего списка пункт Коррелятор. Отобразится окно добавления коррелятора.
-
Введите название коррелятора.
-
Задайте интервал проверок в секундах. По умолчанию интервал равен 300 секундам.
-
Добавьте в коррелятор правила корреляции.
Если коллектор, на котором размещен коррелятор, настроен для работы в режиме распределнной корреляции, он не поддерживает работу императивных правил корреляции. Чтобы добавить правило корреляции:
-
Раскройте дерево каталогов в левой части окна и выберите каталог, который содержит нужное правило корреляции.
-
Установите флажок слева от правила корреляции, которое необходимо добавить в коррелятор.
-
-
Нажмите на кнопку Добавить. Новый коррелятор отобразится на схеме.
Добавим коррелятор с правилом DDoSDetectionRule на конвейер. Укажем в названии "DDoSDetectionRule".
Настройка оповещений
Чтобы корелляционные события, получаемые после срабатывания правил корреляции, генерировали оповещения, необходимо добавить на конвейер сервис оповещений.
Чтобы добавить сервис оповещений, необходимо создать и установить на нем правило сегментации, согласно которому корреляционные события будут распределяться по оповещениям.
Создание правила сегментации
Правила сегментации в системе R-Vision SIEM позволяют управлять потоком корреляционных событий, обеспечивая их агрегацию, классификацию и преобразование в оповещения согласно заданным условиям.
Чтобы добавить правило сегментации:
-
Перейдите в раздел Экспертиза. Система отобразит сведения об имеющихся элементах экспертизы, в том числе их текущий статус (включен/выключен).
-
Нажмите на кнопку Создать и выберите из выпадающего списка опцию Правило сегментации. Система отобразит окно создания правила сегментации.
Пример правила сегментации, схема RObject
# Уникальный идентификатор правила сегментации. id: segmentation/ddos_alerts # Название правила сегментации. name: DDoSAlertsSegmentation. # Тип элемента экспертизы. type: segmentation_rule # Версия правила сегментации. version: 1.0.0 # Описание назначения правила сегментации. description: Сегментация и классификация оповещений для атак типа DDoS. # Имя и контактные данные автора правила сегментации. author: John Doe <johndoe@example.com> # Список совместимых с правилом источников данных. data_source: - platform: Windows - source: Sysmon - events: - logs/default.log - logs/somelog.log # Теги, связанные с правилом сегментации. tags: - ddos - alert - segmentation # Группирует корреляционные события по указанным полям. Если не указано, все события помещаются в единую группу. group_by: - source_ip # Задаёт максимальное количество корреляционных событий в группе оповещения. # При достижении максимального значения создаётся новое оповещение. threshold: 1 # Задаёт максимальное время жизни корреляционных событий в группе. # При достижении максимального значения создаётся новое оповещение. timeout: 60 # Код VRL для формирования имени оповещения (например из частей имён событий). # Выполняется только при создании оповещения (при обновлении существующего оповещения не выполняется). # Если поле не определено, оповещению будет автоматически присвоено название правила корреляции, которое первым привело к его срабатыванию. alert_name: !vrl | "DDoS_ALERT_" + to_string!(.source_ip) # Тесты для проверки работы правила сегментации. tests: - name: High traffic from single source IP events: - { type: "correlation_rule", severity: "high", event_type: "DDoS Detection", source_ip: "198.51.100.1", datetime: "2023-09-28T12:45:00Z" } - { type: "correlation_rule", severity: "high", event_type: "DDoS Detection", source_ip: "198.51.100.2", datetime: "2023-09-28T12:47:00Z" } - { type: "correlation_rule", severity: "high", event_type: "DDoS Detection", source_ip: "198.51.100.1", datetime: "2023-09-28T12:49:00Z" } assertion: !vrl | assert_eq!(length(.), 3) assert_eq!(.[0].group_by.source_ip, "198.51.100.1") assert_eq!(.[0].name, "DDoS_ALERT_198.51.100.1") assert_eq!(.[1].group_by.source_ip, "198.51.100.2") assert_eq!(.[1].name, "DDoS_ALERT_198.51.100.2")Интерпретация
Правило сегментации "DDoSAlertsSegmentation" создано для обработки и классификации корреляционных событий, генерируемых правилом "DDoSDetectionRule", целью которого является выявление DDoS-атак на основе анализа потока событий.
Метаданные правила сегментации:
-
id: уникальный идентификатор правила сегментации в системе. -
name: название правила сегментации, отражающее его назначение, — сегментация оповещений, связанных с DDoS-атаками. -
type: тип элемента экспертизы указывает, что это правило относится к категории правил сегментации. -
version: версия правила сегментации, позволяющая отслеживать его итерации и обновления. -
description: краткое описание назначения правила сегментации — классификация и сегментация оповещений для атак DDoS. -
author: автор правила сегментации и его контактные данные. -
tags: метки, связанные с правилом, такие как ddos, alert, segmentation, помогающие в классификации и поиске правила.
Параметры сегментации:
-
group_by: указывает на поля событий, которые используются для группировки корреляционных событий. В данном случае, этоsource_ip, что позволяет сегментировать события по уникальным источникам IP. -
threshold: количество событий от одного источника, при достижении которого будет сгенерировано новое оповещение. -
timeout: временной интервал (в секундах), в течение которого агрегируются события для сегментации. -
alert_name: код VRL для формирования имени оповещения на основе атрибутов события. В данном случае, IP-адреса источника. Если поле не определено, оповещению будет автоматически присвоено название правила корреляции, которое привело к его срабатыванию.
Тестирование правила сегментации "DDoSAlertsSegmentation":
Поле
testsв правиле сегментации "DDoSAlertsSegmentation" предназначено для верификации и валидации логики правила путем имитации реальных сценариев обработки корреляционных событий. Это позволяет убедиться, что логика сегментации работает корректно и соответствует заранее определенным требованиям к обработке и классификации событий.В данном случае, тестовый блок содержит следующие ключевые компоненты:
-
name: имя теста, в данном случае "High traffic from single source IP", что указывает на цель теста — проверить способность правила сегментации агрегировать и классифицировать события, характерные для DDoS-атак. -
events: перечисление событий, которые имитируют корреляционные события, сгенерированные правилом обнаружения DDoS. Эти события содержат различныеsource_ipи метаданные, характерные для событий обнаружения DDoS, такие, как тип события "DDoS Detection", уровень серьезности "high", и временная метка. -
assertion: содержит скрипт на языке VRL, предназначенный для дополнительной валидации атрибутов каждого сгенерированного оповещения. В частности, проверяется, что имя оповещения соответствует ожидаемому формату, основанному на IP-адресе источника события.
Таким образом, поле
testsобеспечивает комплексную проверку правила сегментации "DDoSAlertsSegmentation", демонстрируя его способность идентифицировать и классифицировать события, ассоциированные с DDoS-атаками, и соответственно генерировать оповещения для дальнейшего анализа и реагирования. -
-
Заполните поля правила сегментации, чтобы определить логику его работы, и нажмите на кнопку Опубликовать версию. Система отобразит уведомление об успешном создании правила. Новое правило сегментации отобразится в таблице раздела Экспертиза.
-
Чтобы созданное правило стало доступным в конвейерах событий, включите его:
-
Нажмите на строку с созданным правилом сегментации. Система отобразит в правой части экрана карточку этого правила с подробной информацией о нем.
-
Убедитесь, что в карточке открыта вкладка Информация.
-
Переведите переключатель состояния правила в верхней части карточки в активное положение и подтвердите включение правила. Система обновит информацию о статусе правила сегментации.
-
Добавление сервиса оповещений
Сервис оповещений позволяет настраивать связи между правилами корреляции и правилами сегментации для распределения корреляционных событий по оповещениям.
Чтобы добавить сервис оповещений на конвейер:
-
Откройте окно конфигурации конвейера, созданного на шаге 5. Убедитесь, что в выпадающем списке в правом верхнем углу окна выбран пункт Черновик.
-
Нажмите на кнопку Добавить элемент и выберите из выпадающего списка пункт Сервис оповещений. Отобразится окно добавления сервиса оповещений.
-
Введите название сервиса оповещений.
-
Выберите из выпадающего списка хранилище с событиями, на основе которых будут формироваться оповещения.
-
Выберите интеграции для отправки оповещений во внешние системы (опционально).
-
Выберите правило сегментации по умолчанию, которое будет применяться ко всем несвязанным правилам корреляции (опционально).
Если правило по умолчанию не выбрано, то все корреляционные события, сгенерированные одним и тем же правилом корреляции и не удовлетворяющие условиям правил сегментации, будут объединяться в одно и то же оповещение.
-
Настройте связи с правилами сегментации.
-
Нажмите на кнопку Добавить связь. Откроется окно добавления связи.
-
Выберите требуемое правило сегментации из выпадающего списка. В окне отобразится дерево всех правил корреляции в системе, которые ещё не имеют связей с другими правилами сегментации текущего сервиса оповещений.
-
Выберите требуемые правила корреляции, установив флажок слева от их названий.
-
Нажмите на кнопку Добавить. Добавленная связь с правилом сегментации отобразится в окне настройки сервиса оповещений.
-
-
Нажмите на кнопку Добавить. Новый сервис оповещений отобразится на схеме.
Добавим на конвейер сервис оповещений с правилом сегментации DDoSAlertsSegmentation, связанным с правилом корреляции DDoSDetectionRule. Укажем в названии "DDoSAlerts".
Настройка шины
Шина позволяет направлять потоки событий между конвейерами. В коллекторе может быть одна или несколько шин. Шина поддерживает два типа соединения: на получение и на отправку событий. Два конвейера событий могут сообщаться друг с другом посредством шины.
Чтобы добавить на конвейер соединение с шиной, необходимо сначала создать шину в коллекторе.
Создание шины
Чтобы создать шину:
-
Перейдите в раздел Ресурсы → Коллекторы. Система отобразит сведения об имеющихся коллекторах, в том числе их текущий статус (включен/выключен).
-
Нажмите на строку коллектора, созданного на шаге 4. Система отобразит в правой части экрана карточку этого коллектора с подробной информацией о нем.
-
Перейдите на вкладку Шины в карточке коллектора. Система отобразит список шин коллектора.
-
В нижней части карточки нажмите на кнопку Добавить. На экране отобразится окно добавления шины.
-
Введите название шины.
-
При необходимости введите описание шины.
-
Нажмите на кнопку Добавить. Шина будет создана и отобразится в списке шин на вкладке Шины в карточке коллектора.
Добавление соединения с шиной
-
Убедитесь, что карточка коллектора, созданного на шаге 4, все еще открыта.
-
Перейдите на вкладку Конвейеры в карточке коллектора и раскройте его карточку нажав на стрелку в строке конвейера.
-
Нажмите на кнопку Конфигурация конвейера в нижней части карточки коллектора. Отобразится диаграмма конфигурации конвейера.
-
Удостоверьтесь, что в выпадающем списке Версия на панели инструментов выбран вариант Черновик.
-
Нажмите на кнопку Добавить элемент и выберите из выпадающего списка пункт Шина. Отобразится окно добавления соединения с шиной.
-
Выберите из выпадающего списка шину, с которой требуется задать соединение. На выбор доступны только шины текущего коллектора.
-
Введите название соединения с шиной.
-
Выберите из выпадающего списка тип соединения с шиной (получение/отправка).
-
Нажмите на кнопку Добавить. Соединение с шиной отобразится на схеме.
Добавим соединение с шиной с названием "BadRequestEvents" и настроим его на получение событий.
Добавление конечной точки
Конечная точка определяет, куда направляются обработанные события, например, в хранилище или на внешний интерфейс. Конечная точка, в зависимости от настроек, пересылает нормализованное событие в хранилище событий, внешнюю систему или сервис оповещений. Имеет один вход и не имеет выходов.
Чтобы добавить конечную точку на конвейер:
-
Откройте окно конфигурации конвейера, созданного на шаге 5. Убедитесь, что в выпадающем списке в правом верхнем углу окна выбран пункт Черновик.
-
Нажмите на кнопку Добавить элемент и выберите из выпадающего списка пункт Конечная точка. Отобразится окно добавления конечной точки.
-
При необходимости выберите шаблон для автоматического заполнения полей конечной точки. По умолчанию выбран вариант Без шаблона.
-
Заполните поля (набор и содержание полей могут отличаться в зависимости от типа точки):
-
Название конечной точки.
-
Тип конечной точки.
-
Формат конечной точки.
-
-
Установите флажок Сохранить как шаблон, если настройку конечной точки необходимо сохранить в качестве шаблона для дальнейшего использования.
-
Нажмите Добавить. Новая конечная точка отобразится на схеме.
Создадим пять конечных точек со следующими названиями: "ServerError", "UnknownError", "HostUnavailable", "DDosDetections", и "170.174.42.191 Status".
Объединение элементов конвейера
Каждый элемент конвейера отвечает за конкретный этап обработки событий. У элемента может быть только один вход и один или несколько выходов, но они могут и отсутствовать. Элементы конвейера связаны между собой направляющими линиями, которые определяют порядок и направление обработки событий.
| Чтобы приблизить или отдалить блоки на схеме, используйте колесо мыши. |
Чтобы связать элементы, наведите курсор на круглую метку, расположенную на его боковой стороне. Курсор примет вид крестика. Перетащите крестик к метке на другом элементе, чтобы установить связь. Порядок обработки событий будет определен логикой этих связей.
Пример настройки конвейера:
-
Соедините точку входа JSON с маршрутизатором StatusCheckRouter.
-
Свяжите точку входа JSON с агрегатором AggregateEvents.
-
Объедините агрегатор AggregateEvents с коррелятором DDoSDetectionRule.
-
Разделите поток событий из DDoSDetectionRule на два направления: к конечной точке DDosDetections и к сервису оповещений DDoSAlerts.
-
Направьте поток из маршрута ClientErrorRoute маршрутизатора к фильтру FilterByHost.
-
Направьте поток из маршрута ServerErrorRoute маршрутизатора к конечной точке ServerError.
-
Направьте поток из маршрута По умолчанию маршрутизатора к конечной точке UnknownError.
-
Разделите поток данных из FilterByHost на два направления: к конечной точке 170.174.42.191 Status и к VRL-трансформации AssignResponseStatus.
-
Направьте поток из AssignResponseStatus к нормализатору Normalization и шине BadRequestEvents.
-
Соедините нормализатор Normalization с конечной точкой HostUnavailable.
| Чтобы удалить связь, выберите её и нажмите клавишу DELETE (macOS) или BACKSPACE (Windows). |
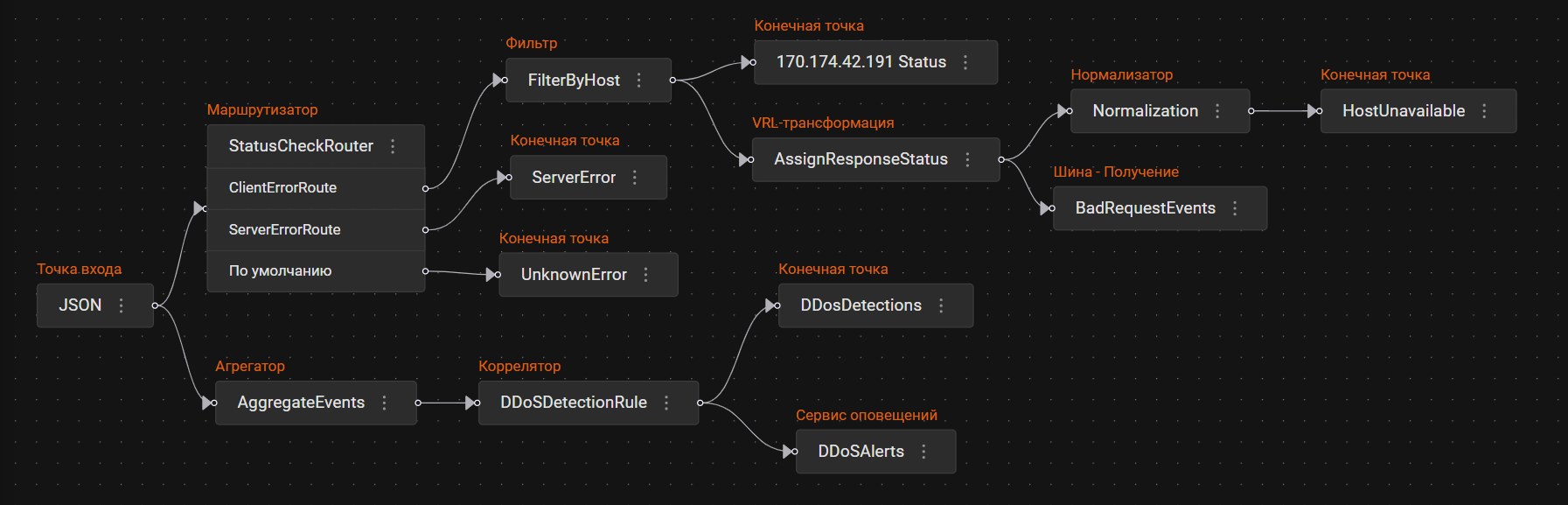
На этот конвейер события поступают через точку входа JSON и разделяются на две ветки: к маршрутизатору StatusCheckRoute и агрегатору AggregateEvents.
Агрегированные события попадают на коррелятор DDoSDetectionRule. Если коррелятор генерирует событие, оно сохраняется в конечную точку DDosDetections, а сервис оповещений DDoSAlerts генерирует соответствующее оповещение. Оповещение можно посмотреть в разделе Оповещения.
В маршрутизаторе StatusCheckRoute данные фильтруются по условиям маршрутов:
-
ClientErrorRoute:
.event.status == "400" || .event.status == "401" || .event.status == "403" || .event.status == "404"Соответствующие условию события двигаются к фильтру FilterByHost.
-
ServerErrorRoute:
.event.status == "500" || .event.status == "502" || .event.status == "504"Соответствующие условию события отправляются в конечную точку ServerError.
-
По умолчанию: через этот маршрут проходят события, не удовлетворяющие условиям остальных маршрутов. Соответствующие события отправляются в конечную точку UnknownError.
В фильтре FilterByHost, данные фильтруются по условию .event.host == "170.174.42.191". Соответствующие события двигаются далее к конечной точке 170.174.42.191 Status, где они записываются в хранилище, и к VRL-трансформации AssignResponseStatus, где им присваивается новое поле resposeStatus.
События из AssignResponseStatus идут к нормализатору Normalization и шине BadRequestEvents. На этапе нормализации поля события трансформируются. Если поле status имеет значение "Bad request", полю severity присваивается значение "high". Затем, эти события отправляются в конечную точку HostUnavailable.
Шаг 7. Включение коллектора и установка конфигурации конвейера
| Для включения конвейера убедитесь, что связанный с ним коллектор уже включен. |
Чтобы события начали поступать в систему и обрабатываться:
-
Перейдите в раздел Ресурсы → Коллекторы. Система отобразит сведения об имеющихся коллекторах, в том числе их текущий статус (включен/выключен).
-
Нажмите на строку коллектора в списке. Система отобразит в правой части экрана карточку этого коллектора с подробной информацией о нем.
-
Убедитесь, что в карточке коллектора открыта вкладка Информация.
-
Переведите переключатель состояния коллектора в верхней части карточки в активное положение. Отобразится окно подтверждения включения коллектора.
-
Нажмите на кнопку Включить. Система обновит информацию о статусе коллектора.
-
Перейдите на вкладку Конвейеры в карточке коллектора. Система отобразит список конвейеров коллектора.
-
Нажмите на стрелку (
) в строке конвейера. Отобразится карточка конвейера. -
Нажмите на кнопку Конфигурация конвейера в нижней части карточки. Отобразится диаграмма конфигурации, над которой расположены кнопки установки/отключения конфигурации конвейера.
-
Удостоверьтесь, что в выпадающем списке Версия на панели инструментов выбран вариант Черновик.
-
Нажмите на кнопку Установить конфигурацию над диаграммой конфигурации. Отобразится окно подтверждения установки конфигурации.
-
Нажмите на кнопку Установить. Система отобразит уведомление о включении конвейера и обновит информацию о статусе конвейера в его карточке.
Теперь события начнут поступать в систему и обрабатываться согласно настройкам конвейера. Все события, которые проходят через конвейер или генерируются на нём, будут сохраняться согласно настройкам конечных точек. Поиск по этим событиям можно осуществлять с помощью языка запросов RQL в разделе Поиск. При обнаружении последовательности событий, соответствующих заданному правилу корреляции, система будет генерировать оповещения.